Multi-tenancy Kubernetes with Virtual Clusters
In this article you will be introduced to the realm of virtual clusters in Kubernetes. We shall explore an innovative solution that not only aids Kubernetes administrators and operators, but also benefits developers and consumers, and hopefully also inspires DevOps enthusiasts alike. By delving into the design and architecture of virtual clusters, we’ll uncover how this solution caters to the diverse scenarios that warrant multi-tenancy within Kubernetes.
Multi-tenancy introduction
In the realm of Kubernetes administration, the term multi-tenancy may sometimes come up. A ‘tenant’ here refers to any entity utilizing the cluster, be it an individual like the cluster administrator, a team like a service’s developers, or even a customer utilizing a semi-managed product. The necessity for isolation between these tenants often arises to address concerns such as authorization & access management, communication security, data privacy, stability within specific environments (production, etc.), maintaining order, and the imposition of custom resource limits per tenant.
Some example use cases that may utilize a multi-tenancy approach in Kubernetes are:
- Management of distinct environments such as staging or testing.
- Providing individual developers (or teams) with separate environments for their work.
- When a company provides a managed product that is Kubernetes-deployable, having a segregated instance of the application for each customer ensures a tailored experience.
- As a teaching instrument for onboarding or training labs, providing isolated sandbox environments.
Traditional multi-tenancy approaches (and their drawbacks)
In considering traditional approaches to multi-tenancy in Kubernetes, it’s crucial to weigh their advantages and drawbacks.
One method that instantly comes to mind involves utilizing multiple clusters. However, this approach is highly expensive due to the need for extensive [cloud] infrastructure, and because the process of spinning up new clusters is notably slow (often many tens of minutes). Moreover, managing this plethora of clusters demands a significant amount of effort.
Alternatively, the second method that comes to mind is Kubernetes Namespaces. However, this approach also presents its limitations - an application within a namespace is restricted to that namespace alone, preventing creation of cluster-wide (non-namespaced) resources, like ClusterRoles or Custom Resource Definitions (CRDs). Furthermore, Kubernetes namespaces are designed for providing logical organization, and may fall short in delivering stringent security isolation (yes, RBAC can indeed restrict access by namespace, but then one literally has only a single layer of security).
Enter VCluster
VCluster (Virtual Clusters) by Loft allows spinning up virtual clusters within an existing host Kubernetes cluster. These virtual clusters function as fully operational Kubernetes clusters. Similarly to virtual machines, virtual clusters utilize/share a single host cluster’s resources into distinct virtual clusters, effectively accommodating multiple tenants.
Each virtual cluster operates autonomously, complete with its dedicated control plane and datastore (equivalent to etcd), encapsulating the essence of a standalone Kubernetes environment. The workloads and services within a virtual cluster appear entirely normal, whilst, under the hood, they are actually scheduled on the host cluster and into a single designated namespace. This arrangement preserves flexibility (to use multiple namespaces) within the virtual cluster while maintaining order within the host cluster.
VCluster’s CLI utility may be installed with a simple
curl one-liner (see the
installation instructions in VCluster’s
getting-started guide) or -if using a Mac- with
brew.
By the way, all of this is open source..!
Basic Usage
This article’s focus is on the concepts and theory around and behind virtual clusters. In order to get a taste of VCluster’s practical aspects, refer to its quickstart guide available in the VCluster documentation. Additionally, the VCluster documentation also provides many details about various aspects of the administration and operation of VClusters, such as the Operator guide or Configuration reference.
Comparison to traditional multi-tenancy approaches
The following table (from VCluster’s official documentation) clearly summarizes how VCluster delivers the best of both worlds, when providing multi-tenancy approaches:
| Namespace for each tenant |
VCluster | Cluster for each tenant |
|
|---|---|---|---|
| Isolation | ✗ very weak | ✔ strong | ✔ very strong |
| Access for tenants | ✗ very restricted | ✔ vcluster admin | ✔ cluster admin |
| Cost | ✔ very cheap | ✔ cheap | ✗ expensive |
| Resource sharing | ✔ easy | ✔ easy | ✗ very hard |
| Overhead | ✔ very low | ✔ very low | ✗ very high |
(table data source: https://www.vcluster.com)
VCluster provisioning methods
Provisioning virtual clusters (VClusters) within Kubernetes can be achieved in various methods:
CLI
The VCluster CLI provides an imperative approach to provisioning,
allowing for rapid outcomes. The virtual clusters may receive basic
configuration through various CLI flags, or in-depth configuration by
passing a configuration file. The configuration files are actually just
Helm values.yaml files, this convenient feature is due to
the VCluster CLI actually just being a wrapper of the Helm
implementation. The VCLuster CLI is most convenient for management
tasks, with commands such as vcluster ls or
vcluster connect ....
Helm
Well known to many DevOps engineers and Kubernetes administrators, Helm offers a familiar approach to declaratively provisioning virtual clusters via the official VCluster Helm chart. Besides streamlining the standard operations, Helm allows one to operate VClusters in a standalone manner, with no additional dependencies (no need even for the CLI!), and is highly suited for provisioning VClusters via GitOps practices.
Terraform
VClusters may also be provisioned using Terraform via a dedicated Terraform provider. This method is ideal for operators who rely on Terraform and want to include their virtual clusters as part of their infrastructure as code. More details can be explored through the VCluster Terraform provider’s documentation.
Between these provisioning methods, administrators can easily choose the approach that aligns best with their workflow, ensuring an efficient and tailored provisioning process for VClusters within their Kubernetes environment.
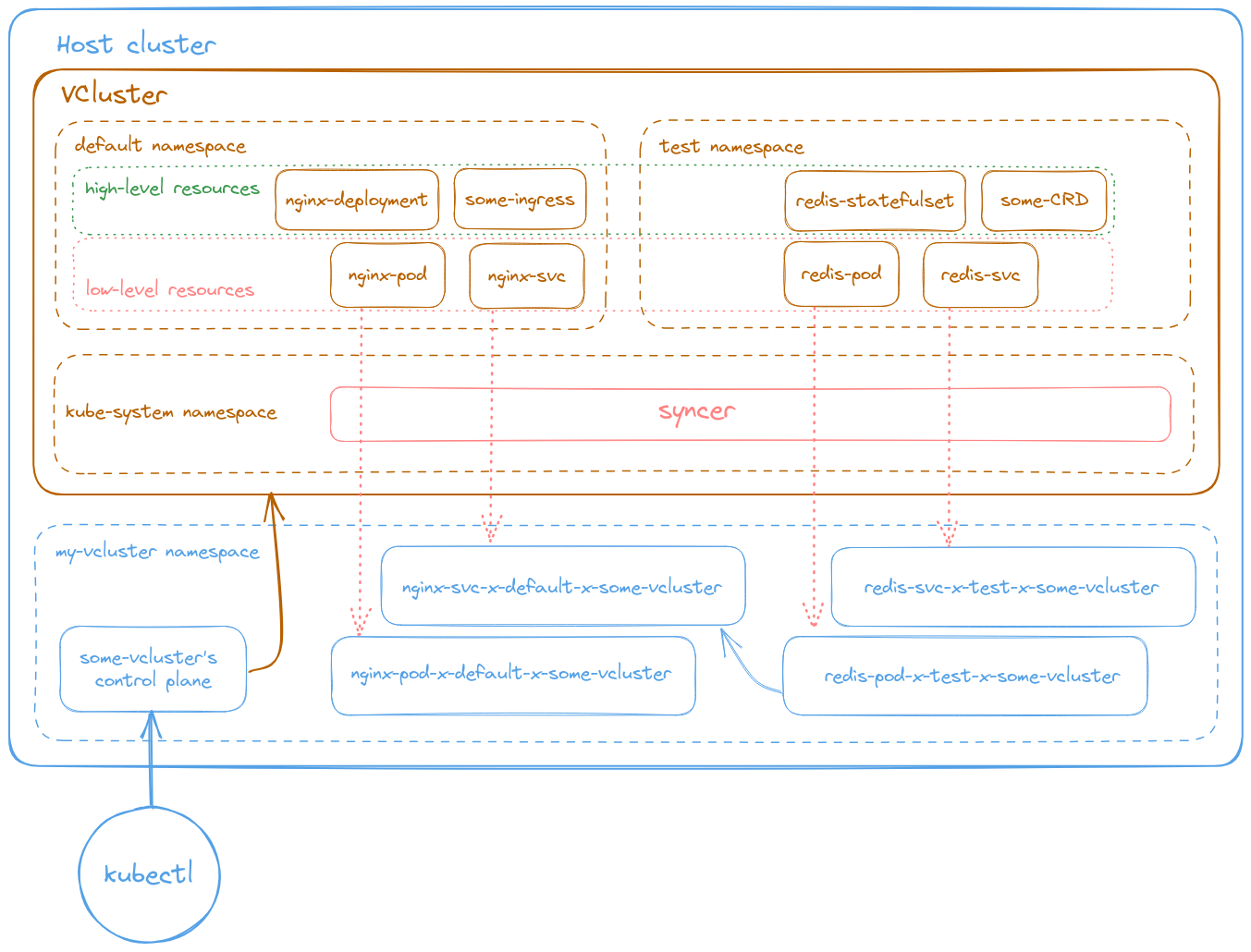
Architecture
A pillar in VCluster’s architecture design involves categorizing Kubernetes resource kinds as high-level and low-level:
- High-level resources - Reside only within the virtual cluster, and respectively, their state is registered only in the virtual cluster’s data store. Some examples of high-level resources are Deployments, StatefulSets, Ingresses, ServiceAccounts, CRDs, or Jobs.
- Low-level resources - Appear normally within the virtual cluster, however, they are also synchronized into the host cluster (more on this below) - where they are organized/isolated into a single host Namespace.
Within the host cluster VClusters are deployed as a StatefulSet, which manages a single Pod comprised of two containers:
- The Control Plane - Which bundles the standard Kubernetes components such as the API server, controller manager, and the data store (classically [etcd] or SQLite) in a singular Kubernetes distribution (by default k3s).
- The Syncer - Which is the workhorse behind VCluster. The Syncer’s role mainly comprises of copying low-level resources from the virtual cluster to the underlying host cluster.
Furthermore, due to their streamlined design, VClusters even provide the flexibility to support nested VClusters.
Distributions
When deploying a VCluster, one may use any of the certified Kubernetes distributions. The default choice is k3s (known for its small footprint and wide adoption). Additional possibilities include k0s or EKS anywhere, and, of course, Vanilla k8s (the CNCF’s official version).
Resource names’ structure
Within the virtual cluster, Kubernetes resources are named normally
(<resource name in vcluster>) and may reside in any
desired namespace. This provides the expected and conventional behavior
for its tenants (users and administrators alike).
In the host cluster, where the low-level resources are
synchronized, they reside in a single namespace and are automatically
named (by the Syncer container) using the following structure:
<resource name in vcluster>-x-<namespace in vcluster>-x-<name of vcluster>.
Besides preventing resource name conflicts (e.g. same name but different
namespaces, within the virtual cluster), this format also helps maintain
order, and allows simple identification of resources for management by
host cluster administrators.
Cleanup
Deleting a VCluster (or even simply deleting its namespace from the host cluster) will always be possible and graceful, with no negative impacts on the host cluster (no “zombie” resources stuck in a termination state, etc.). This is smartly implemented by:
- VClusters do not affect the host cluster’s control plane nor add any server-side elements.
- The VClusters’ StatefulSets and any other resources, all have appropriate owner references, thus if the VCluster is deleted, everything that belongs to it will be automatically deleted by Kubernetes as well (via a mechanism similar to how deleted Deployments clean up their Pods).
Caveats
For the most part, VCluster works very well due to its simplicity and should cater well to many basic and moderate use cases. However, under certain more advanced conditions, some complications or issues may arise. The following list is not exhaustive, but covers several examples and some experience from my work with it:
- StorageClasses - Despite dynamic storage
provisioning and persistence functioning fine, one may notice that - by
default - no StorageClass resources exist in the VCluster. A workaround
to this would be to use custom
configuration for the Syncer by setting
sync.hoststorageclasses.enabled=true. - DaemonSets - By default, VCluster will
create/display “fake nodes” because it has no RBAC permissions (by
default) to view the real nodes of the underlying host cluster. This may
lead to misbehavior of DaemonSets, such as preventing scaling-in nodes.
A workaround to this would be to configure
the synchronization of Nodes and set an appropriate mode (such as
sync.nodes.enabled=true&sync.nodes.syncAllNodes=true). - Network Policies By default, VCluster ignores
Network Policies. However, one can enable synchronization of them to the
host cluster by setting
sync.networkpolicies.enabled=true, thus achieving the desired traffic behavior. It should go without saying that this feature relies on the support of Network Policies by the host cluster’s CNI. - Pod Schedulers - In the niche cases one wishes to use a custom Pod Scheduler, it’s essential to recognize that they are not supported by all the Kubernetes distributions available in VCluster. This is due to the fact that Pods are considered low-level resources, and the actual scheduling of them is managed by the host cluster’s scheduler.
Understanding and navigating these caveats will empower users to make informed decisions and effectively leverage VClusters while considering their specific use cases and requirements.
Conclusion
In conclusion, we familiarized ourselves with the concept of multi-tenancy in Kubernetes, and touched on various scenarios that call for multi-tenancy. We compared traditional multi-tenancy approaches in Kubernetes with VCluster, and learned how VCluster provides us with a “best of both worlds” solution.
We explored VClusters from a Kubernetes cluster administrator’s perspective, focusing mainly on theoretical concepts and architectural aspects, such as the way VCluster handles high and low-level resources - synchronizing only the low-level resources to the host cluster. We addressed several caveats and discussed the nature of their causes and how to potentially work around them, giving us a peek into the finer configuration that is available when provisioning VClusters.
So, if you were in the search for a streamlined multi-tenancy solution within Kubernetes, are a DevOps enthusiast, or even simply a Kubernetes administrator (or all of them) - then this overview article may have introduced you to your next big tool, or simply provide you with a handy utility for toying around with sandbox environments. Either way, VClusters proves to be a flexible and powerful tool, empowering users to optimize their multi-tenant Kubernetes environments, fostering security, isolation, and streamlined management.
Sources & additional info
- VCluster documentation - A great place to get started or dive into the advanced.
- VCluster Helm chart - More than enough to get up and running without installing anything else.
- VCluster Terraform provider - For managing via Terraform.
- Loft - A non-free software that assists in managing VClusters by web GUI or CLI, creating templates, integrating with SSO, and more.
- Loft Slack - VCluster official community Slack.